Back
Similar todos
try to debug 99% DB CPU
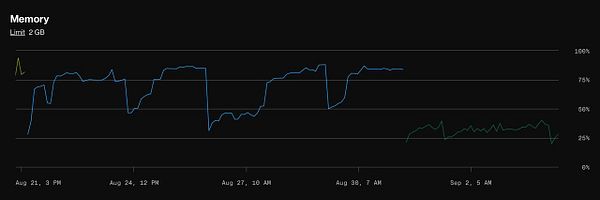
Upscale prod server to double CPU and double mem because mem was too high before, now it's all good  #prompthero
#prompthero
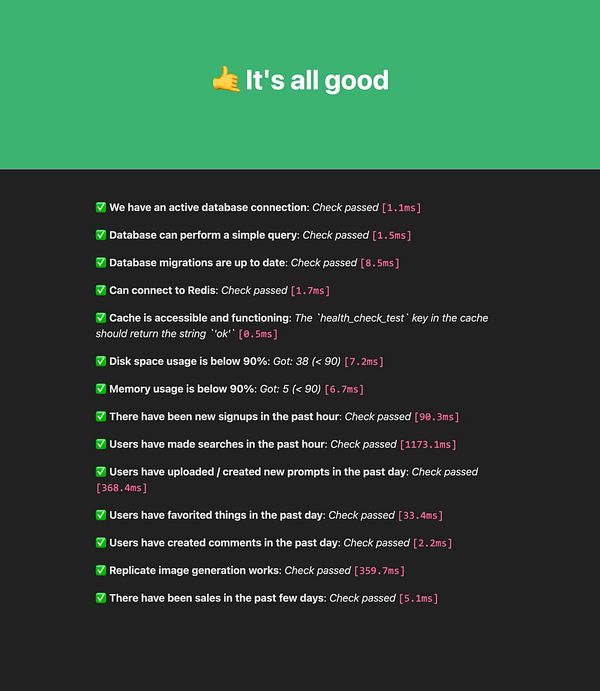
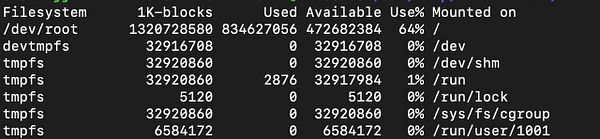
Crashed the prod this morning, and still cannot understand why the mem leak happen.
I'm bisecting file by file  #capgo
#capgo
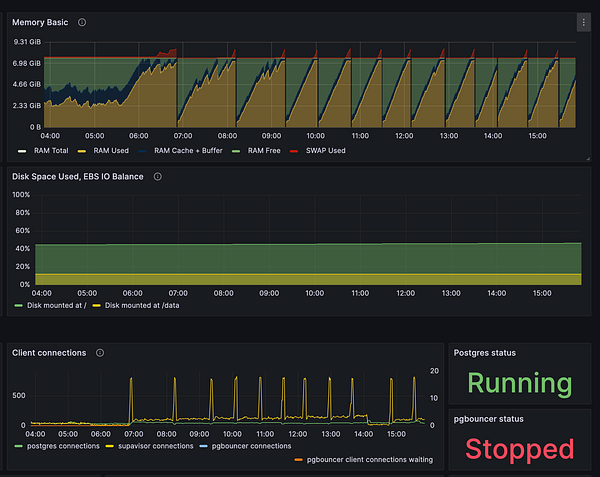
optimise performance from 18% to 90+  #freelancegig
#freelancegig
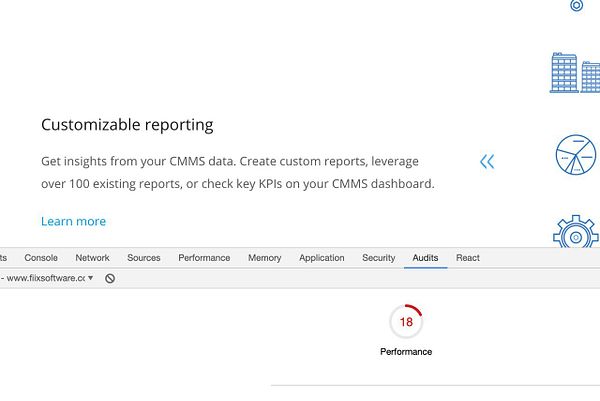
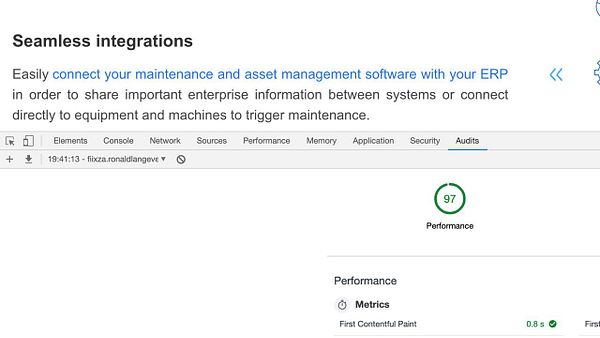
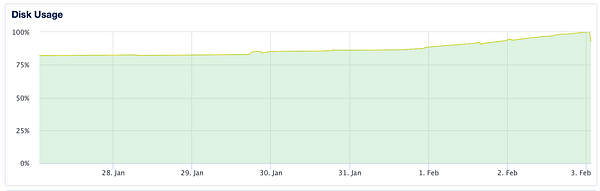
figure out why diskusage is near 100% on test server
fix db cpu issue
Service is degraded with a "1024 worker_connections are not enough" error on my backend servers. Trying to increase but everything is at 100% CPU 🥲  #blocksender
#blocksender
fixed db cpu spikes
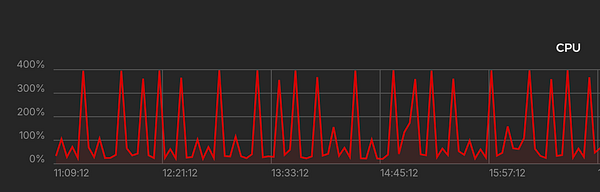
survive weird memory error that crashed app and then solved by itself  #appointclinic
#appointclinic
reboot  #tweetsweeper server... need to figure out where im leakin memory
#tweetsweeper server... need to figure out where im leakin memory
wake up from mayhem with my NVIDIA A16s, 70% of them were down all night and only fixed this morning by Vultr. A40 for large LLM still up fortunately  #crisp
#crisp
Clean up some files (like huge log files!) from my server, because I hit 100% usage and sites crashed
See huge memory drop after enabling jemalloc for my Rails app  #startupjobs
#startupjobs