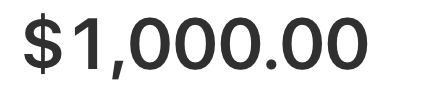Back
Similar todos
experience 6 hours GPU total downtime at Vultr, knocking down all  #mirage AI services, will migrate to Scaleway cause Vultr are 🤡
#mirage AI services, will migrate to Scaleway cause Vultr are 🤡
spend 1h debugging some k8s complexity-induced issue after a node failure at cloud provider for  #crisp mirage gpus
#crisp mirage gpus
fix broken nvidia a100 gpu server at vultr which has put #crisp mirage down for whole night due to being out-of-stock and no replacement physical node could be allocated
Fixing downed servers for the 3rd time in a week and tweet about it x.com/ScottWRobinson/status/1…  #blocksender
#blocksender
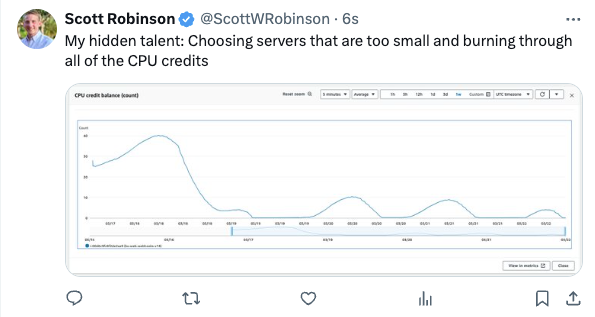
try to upgrade #crisp Mirage AI Kuberbetes cluster version, miserably fail at it cause of broken GPU image NVIDIA drivers from the cloud provider which stalled the upgrade process, destroy cluster and rebuild all infrastructure from scratch all evening 🥲
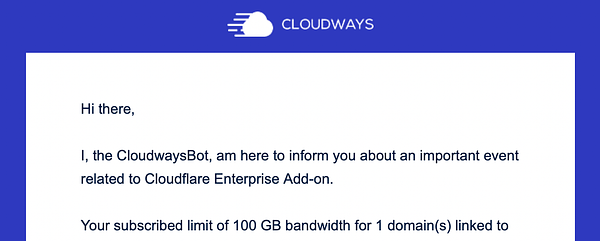
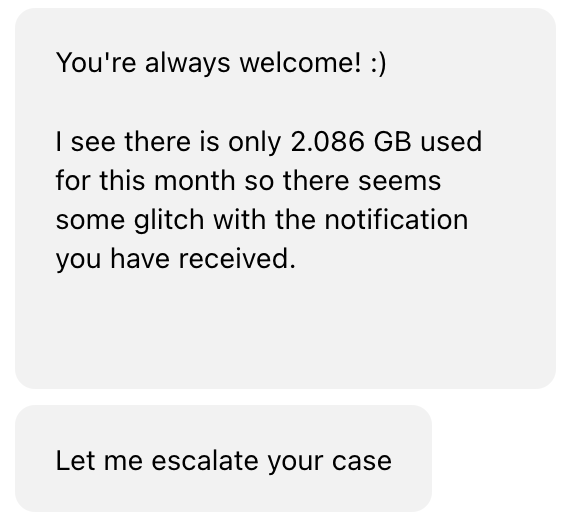
wake up from mayhem with my NVIDIA A16s, 70% of them were down all night and only fixed this morning by Vultr. A40 for large LLM still up fortunately #crisp
get cloudflare incident acknowledged that plagued me for 4 days  #spectate
#spectate
appear to have fixed a production latency by tweaking resources + procfile... but it has been a day of tinkering 💀  #wfhland
#wfhland
Experience hetzner network issues again, still down even after they acknowledged it on phone. 6 hours and counting.
Client invoice issues ~for 13 hours~ 🫠
Spent big part of the day with a production issue that couldn't be hot-fixed quickly while an event with 350+ people was happening. Javascript could be more permissive sometimes 🤦♂️

Finally get the backend deployed after fighting with AWS bugs for the entire day  #unblockdomains
#unblockdomains
Move back  #highscoredomains again back to aws & cloud66 since render seem to be down more offer these days
#highscoredomains again back to aws & cloud66 since render seem to be down more offer these days
pay $1000 for more GPU credits  #interiorai
#interiorai