Back
Similar todos
deploy  #crisp mirage ai improvements to production all morning
#crisp mirage ai improvements to production all morning
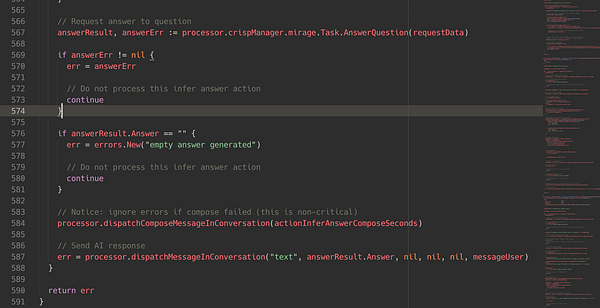
finish some #crisp chatbot ai inference code going to mirage api which manages all our gpus
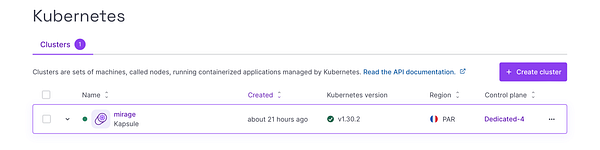
Upgrade k8 cluster at work
benchmarking NVIDIA A16 vs A40 vs A100 GPUs economics to scale #crisp mirage
finish migrating  #mirage kubernetes intel and nvidia gpu instances to scaleway, getting last-generation NVIDIA L40S + L4 GPUs, running much smoother now! (previously: old A40 and A16)
#mirage kubernetes intel and nvidia gpu instances to scaleway, getting last-generation NVIDIA L40S + L4 GPUs, running much smoother now! (previously: old A40 and A16)
fixing rust async-await issues on #crisp mirage ai
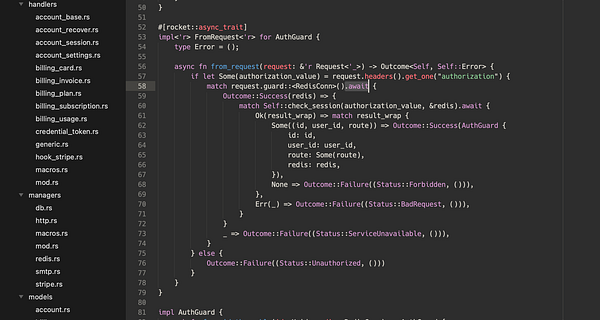
update k8s cluster #badal
publish first production-ready mirage api pod for #crisp ai features
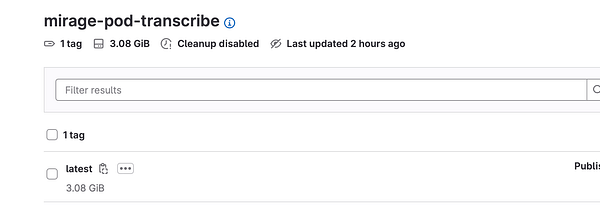
watching #crisp mirage ai come alive
compile and upgrade kernel, amdgpu drv and linux-firmware #qubesos
fix more rust problems on #crisp mirage ai
Finished home AI server build: 2 x 2697v2, 128 GB ram, 2 x Nvidia Tesla P40 24 GB gpus.  #2markdown
#2markdown

Upgrading GPU to rtx 4070ti

finish #crisp mirage ai api
Upgrade staging k3s cluster  #noticeable
#noticeable
adding a plan to upgrade my kubernetes clusters
take down separate vm for data processing b/c needs cuda & azure doesn't let me use their credits to access nvidia gpus 👎  #mused
#mused

Fix a k3s cluster issue with  #ipregistry
#ipregistry
finally ready to migrate #mirage kubernetes gpu cluster from vultr to scaleway!