Back
Similar todos
fix broken nvidia a100 gpu server at vultr which has put  #crisp mirage down for whole night due to being out-of-stock and no replacement physical node could be allocated
#crisp mirage down for whole night due to being out-of-stock and no replacement physical node could be allocated
experience 6 hours GPU total downtime at Vultr, knocking down all  #mirage AI services, will migrate to Scaleway cause Vultr are 🤡
#mirage AI services, will migrate to Scaleway cause Vultr are 🤡
Wake up at 4am with alarms due to a large DDoS targeting #crisp
try to upgrade #crisp Mirage AI Kuberbetes cluster version, miserably fail at it cause of broken GPU image NVIDIA drivers from the cloud provider which stalled the upgrade process, destroy cluster and rebuild all infrastructure from scratch all evening 🥲
Wake up and see that auto recovery is working - as when I went to sleep it was blocked by X - and when I woke up it was refreshed enough times to start working again, going to deprioritize further work on this for now  #watchdog !private
#watchdog !private
do not sleep during whole night cause something has been ddos-ing #crisp help centers hard for the last 6+ hours
spend 1h debugging some k8s complexity-induced issue after a node failure at cloud provider for #crisp mirage gpus
get awaken at 2am because of #crisp downtime
finish migrating #mirage kubernetes intel and nvidia gpu instances to scaleway, getting last-generation NVIDIA L40S + L4 GPUs, running much smoother now! (previously: old A40 and A16)
ran a few dozen backups all night
FINALLY  #capgo is back on track after 24h downtime, what a ride, all decided to broke in the same time
#capgo is back on track after 24h downtime, what a ride, all decided to broke in the same time
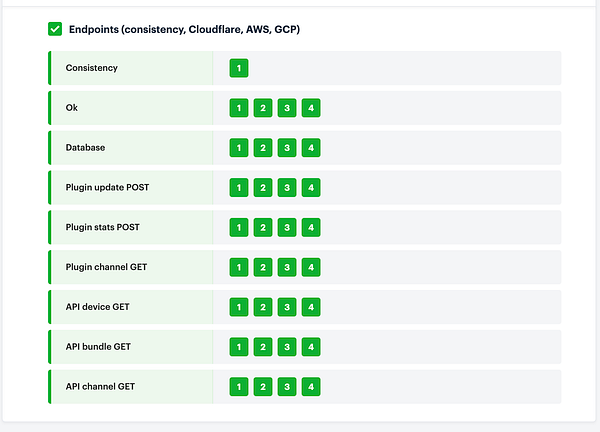
updated  #dotfiles and only had to partially restore my machine 🙄
#dotfiles and only had to partially restore my machine 🙄
deploy #crisp mirage ai improvements to production all morning
get awaken at 2am with total downtime alert for #crisp due to memleak (?) in cloudflare tunnel daemon on server
sleep late this morning to recover from yesterday's DDoS in the early morning  #life
#life
contact Hetzner because of random reboots during the night  #spectate
#spectate
provision batch of L4 and L40S GPUs at Scaleway for #mirage since our account got validated and quotas lifted