Back
Similar todos
Load previous page…
setup more powerful vm for processing data & training models  #mused
#mused
get 108k+ runs on my public speech to text pipeline replicate.com/thomasmol/whisp…

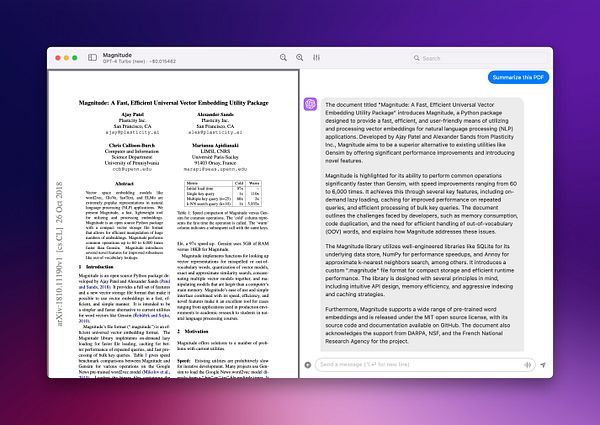
Finally added support for new embedding model (text-embedding-3) and the new GPT 4 Turbo (0125) for  #pdfpals
#pdfpals
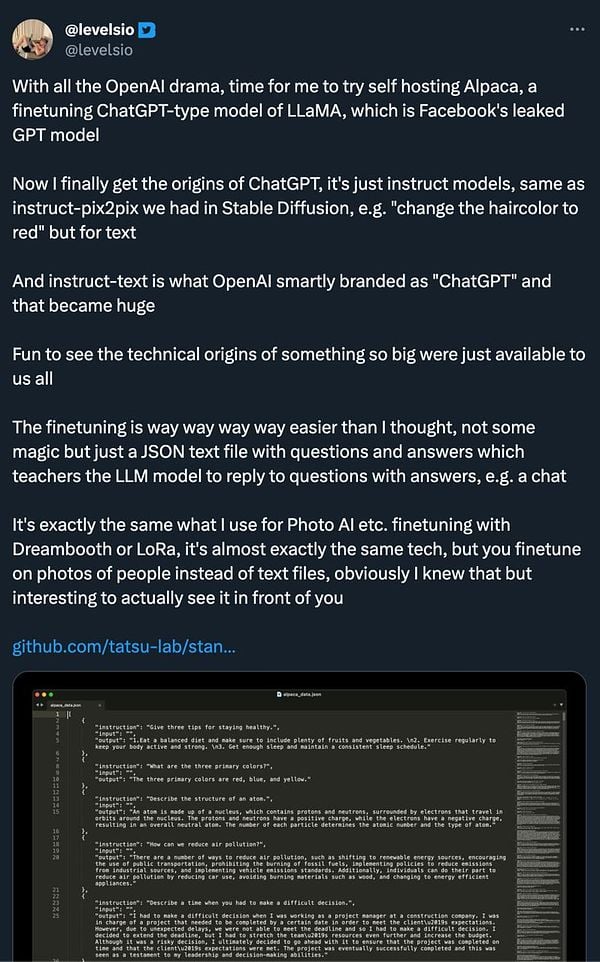
talk about LLM finetuning and Alpaca and ChatGPT being just instruct-text model  #life fxtwitter.com/levelsio/status…
#life fxtwitter.com/levelsio/status…
write article about how we reduced an API endpoint from 16s to 3s  #blog2
#blog2
did more sweep.dev updating with the new open ai 128k context size. I wasn't seeing any improvements though
Switch from real-time inference to Dataframe-inference
Switched all low-fidelity AI tasks model from 3.5-turbo to the newest gpt-4o-mini.  #retently
#retently

update transcribe model to whisper v3 for  #audiogest
#audiogest
Reprocess sphinx data to have full but smaller dataset for developing #mused
Test batching inference  #lyricallabs
#lyricallabs
render out two videos from neural networks on tiny datasets to test new method of capture & pipeline #mused