Back
Similar todos
Load previous page…
relaunched the scraping machine  #thecompaniesapi
#thecompaniesapi
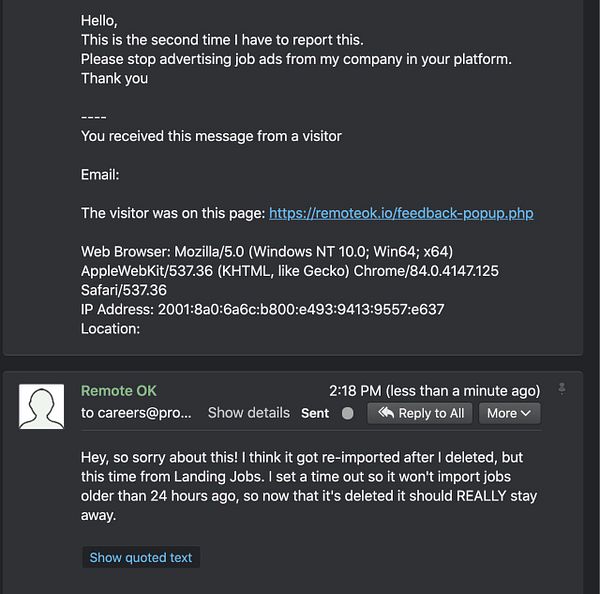
fixed bug in cron crawler job  #sportstechjobs
#sportstechjobs
fix bug where scraper wouldn't skip if no job was found  #plumberjobs
#plumberjobs

add request timeout  #hour
#hour
I just pushed an update that: Has 3,000 URL max per scrape; Prints to sheet in batches of 10 as it scrapes; Will continue scraping even if you close sheets, log out, etc.; Will continue scraping past the previous 6 minute timeout restriction  #infinityxml
#infinityxml
check why scrapping stopped to wprk  #capgo
#capgo
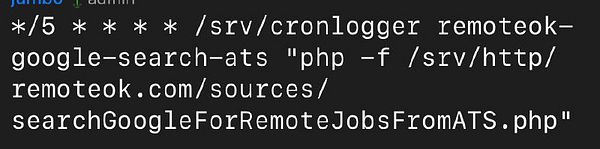
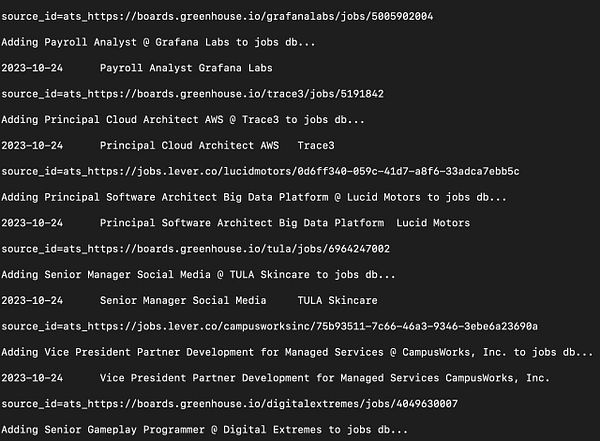
Figuring out backup scrapers...
Setup an event on EventBridge to run the scraper lambda every night  #domainwatchman
#domainwatchman