Back
Similar todos
Load previous page…
Disable runtime metrics to make FTP workers work  #nivoda
#nivoda
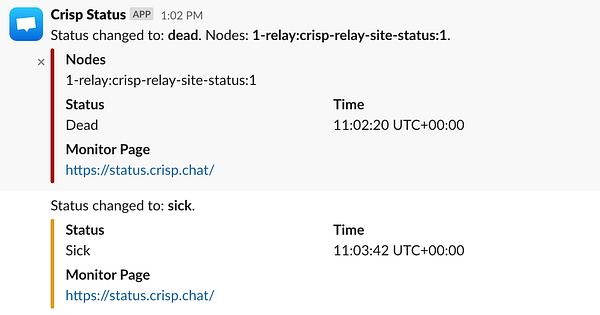
get saving of uptime metrics working  #httpscop
#httpscop
Dodge downtime on #pingr
obsess over running metrics for 30min
work on metrics and release agent update  #spectate
#spectate
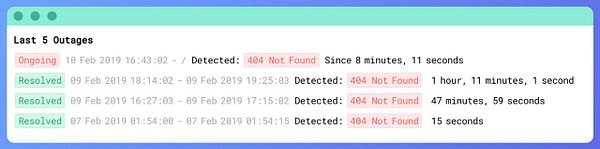
fix issues with  #crisp status page due to overload
#crisp status page due to overload
work on metrics endpoint #spectate
fix timezone issue with network reporting
fix issue too long request stats  #capgo
#capgo
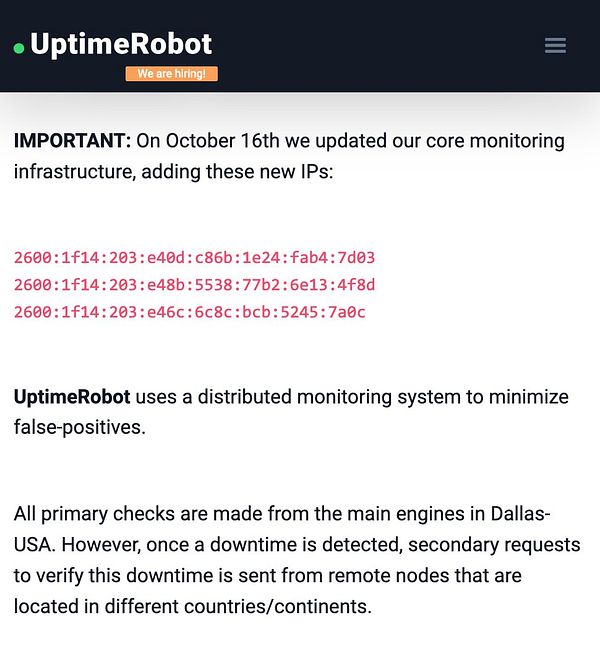
Fix UptimeRobot constantly failing because new 5 days ago UptimeRobot added new IPs and those were not whitelisted by CloudFlare and thus all monitors pinged from these IPs were constantly failing  #prompthero
#prompthero

fix puma not working after restart server
update frontend #downtime