Back
Similar todos
fix clickhouse server that was suffering from 200GB worth of log tables  #spectate
#spectate
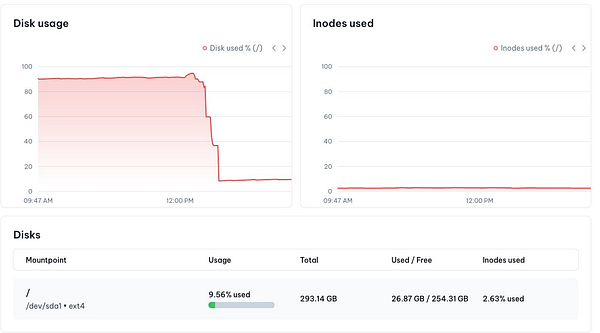
look into clickhouse
work on replicating local  #crisp analytics clickhouse into a cluster
#crisp analytics clickhouse into a cluster
enable storage logs and stats  #apercite
#apercite
import new #crisp analytics clickhouse data to production cluster and it's FAST

continue reviewing new #crisp analytics based on clickhouse
re-import all #crisp analytics data once again to clickhouse, after a change of schema to fix some duplicates
Wrote a simple screenshot logs ingestion logic to ClickHouse from MySQL for  #screenshotone. Should I deploy to production? 🤔
#screenshotone. Should I deploy to production? 🤔
improve logs, change logs location  #wt
#wt
add persistent logs  #shipr
#shipr
Free up HDD on Linode server by deleting logs and old database exports
improve server logging  #backpacklanguage
#backpacklanguage
Improve series reliability and logging  #saasco
#saasco
Improve logging  #trici
#trici
import clickhouse into #crisp development tools for new upcoming analytics engine
Improve DB performance
setup 7 day log retention for error tracking  #codebird
#codebird
decrease Postgres shared buffer from 4GB to 2GB  #startupjobs h/t @daniellockyer
#startupjobs h/t @daniellockyer