Back
Similar todos
Publish new episode of "Next In AI", about the foundational Google paper revealing the secret of o1
open.spotify.com/episode/3Lcu…
[Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters] #nextinai
experiment with different scaling policies to optimize performance and cost  #lyricallabs
#lyricallabs
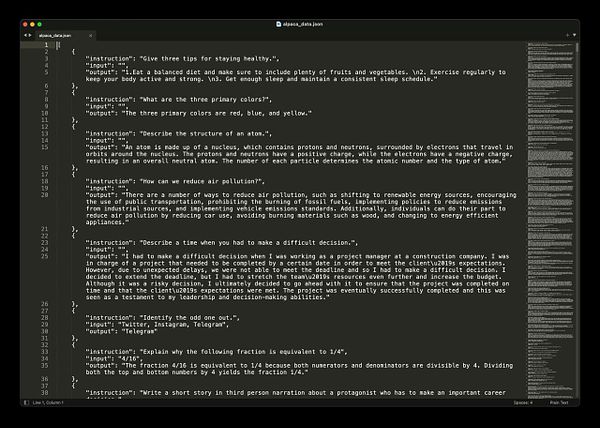
talk about LLM finetuning and Alpaca and ChatGPT being just instruct-text model  #life fxtwitter.com/levelsio/status…
#life fxtwitter.com/levelsio/status…
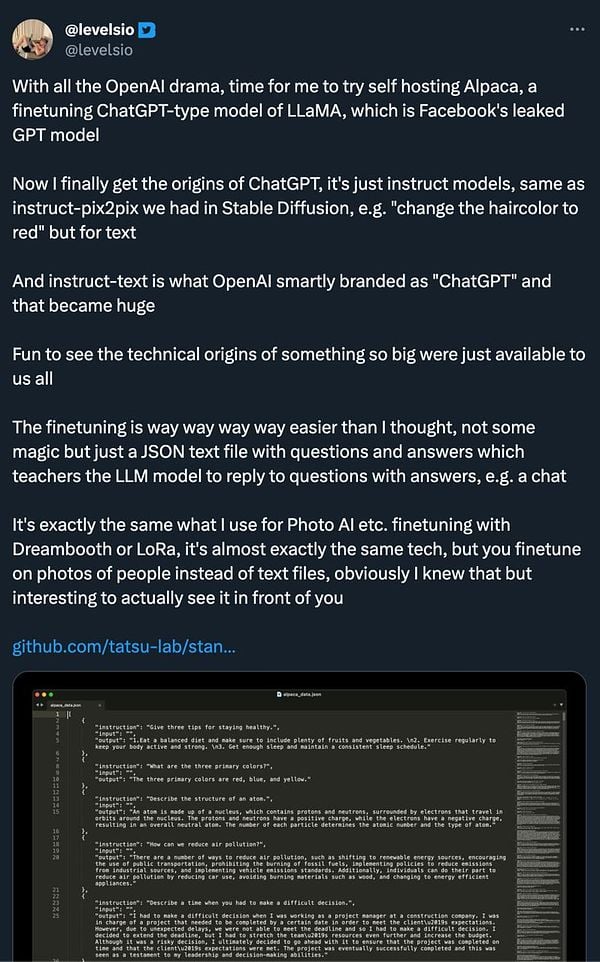
draw scalability  #serverlesshandbook
#serverlesshandbook
🧑🔬 researching when Llama 2 is as good or better than GPT-4 and when it's not as good. Good read here www.anyscale.com/blog/llama-2…
Ran some local LLM tests 🤖
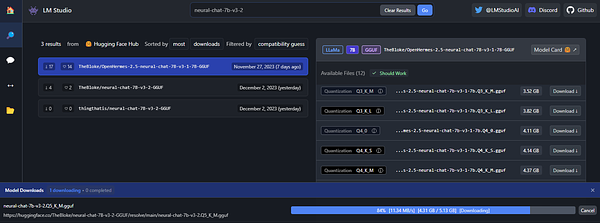
scale down test agents  #teamci
#teamci
NN experimentation #learning





write about scaling teams  #blog2
#blog2
wrote high scalability article
Today's reading arxiv.org/pdf/2305.20050
cache recs for longer to save on model inference costs  #pango
#pango