Back
Similar todos
Load previous page…
⬆️ upgraded the running website and looked at refreshing data scrapers that pull in race info
Automate data fetch and processing  #remoteindex
#remoteindex
🔨 Updates scraper-proxy tool and rewriting/refactoring from the ground up to handle structured data
✨ adds two place importers/scrapers
release improvement to datadog integration  #instatus
#instatus
crushing the backlog.  #jsonify now got multiple locations too (via Brightdata proxy for now)
#jsonify now got multiple locations too (via Brightdata proxy for now)
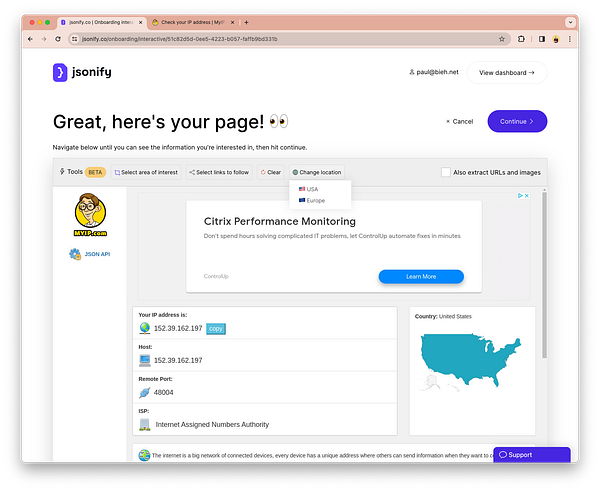
🎉 deployed, re-indexed all events, and confirmed that geo data now gets imported.
finally commit lots of data fetching improvements  #checkoutpage
#checkoutpage
🚜 refactored core events and place scraper to be in its own core app
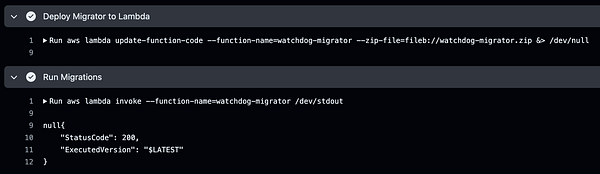
Finish a web scrapper that make the process of adding bulk new quality replays in a matter of 3 clicks  #demtovideo
#demtovideo
build more scrapers  #pagesonpages
#pagesonpages
push import data feature to prod  #buildingo
#buildingo