Back
Similar todos
finished out my day updating scraper-proxy to support css and xpath selectors along with a few features I haven't seen anyone do yet.
worked on how to test/keep a scraping project updated more easily
Rewrote scraper. Second attempt is always significantly better than the first one.
Updated the way I process the scraping data to minimize errors  #bagsoup
#bagsoup
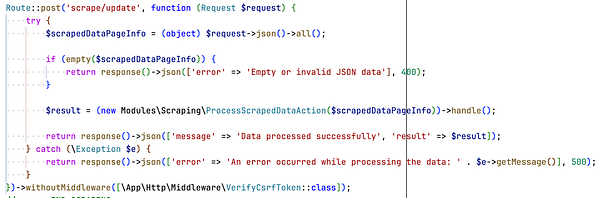
Updated scraper and hand-curated jobs to  #jobsinenglish
#jobsinenglish
finally finished scraper and data looks good. a few hard refactors but I have a pretty good handle on spatula now.
✏ more work on new scraper to get more events  #conf
#conf
working on some a few scrapers for pulling in data vs. just using sheets  #daysuntillatenight
#daysuntillatenight
worked on two new  #jobs scrapers using RSS
#jobs scrapers using RSS
added healthchecks to  #djangonews, #jobs, scraper-proxy, and a few other projects
#djangonews, #jobs, scraper-proxy, and a few other projects
build more scrapers  #pagesonpages
#pagesonpages
new scrapers for  #sportsjobs
#sportsjobs
add a new scraper for  #devopsprojectshq
#devopsprojectshq
Start work on first scraper  #plumberjobs
#plumberjobs
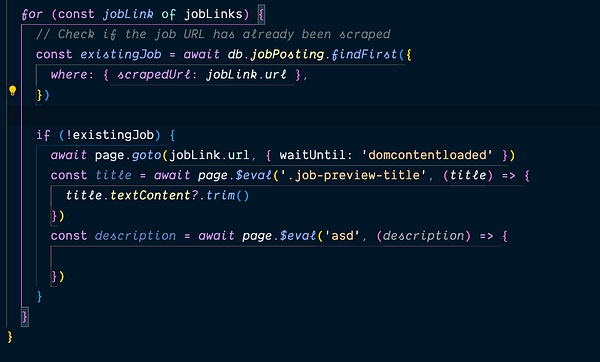
more scraper-proxy work (up to 31 deploys this month) and worked on selector logic and automation.
Prepare scrapers code for batches and pagination  #mrscraper
#mrscraper
late night hacking on a scraper project and mostly getting the UI updated
working with Pandas (Python) to update a few existing scrapers. It's really, really nice but I ran into a bug trying to pull URLs that I don't want to think about right now.
updated scraper logic to fix tags and author information along with some easy to update tests to make this much easier to find/fix next time around