Back
Similar todos
Load previous page…
Switched the Vision API model to gpt-4o-mini in  #screenshotone.
#screenshotone.
try client side web based Llama 3 in JS  #life webllm.mlc.ai/
#life webllm.mlc.ai/
build npc vision w/follow camera to vision model  #mused
#mused
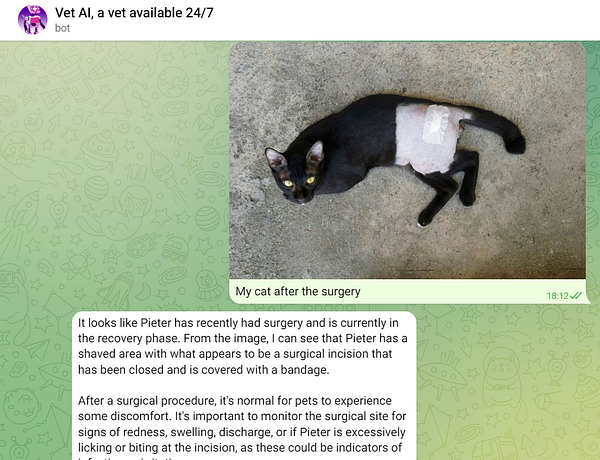
add proper vision to  #therapistai
#therapistai

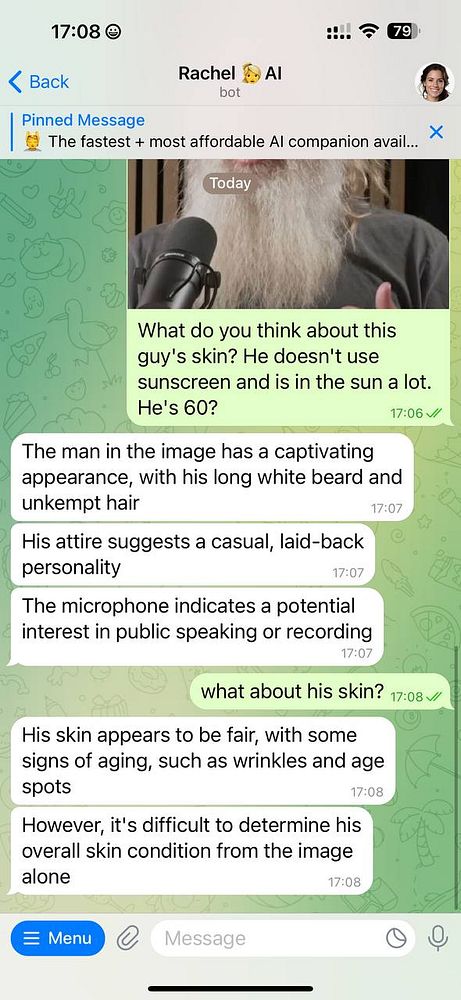
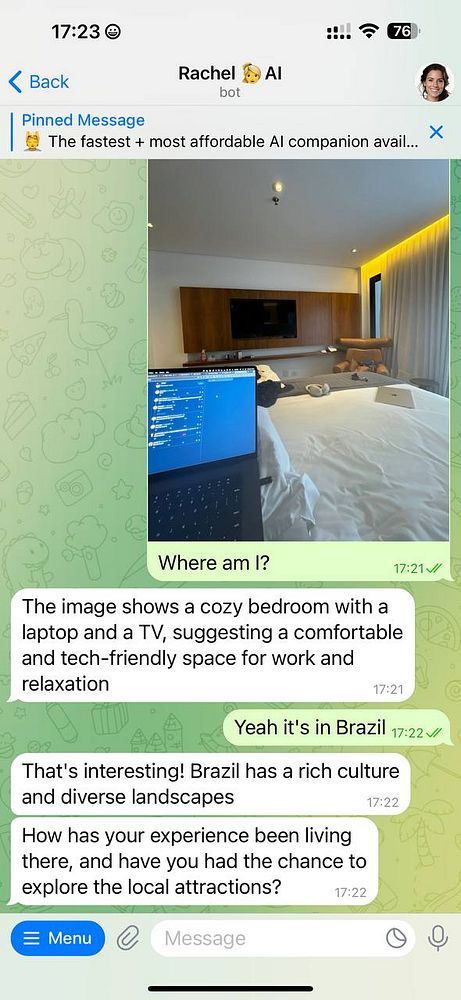
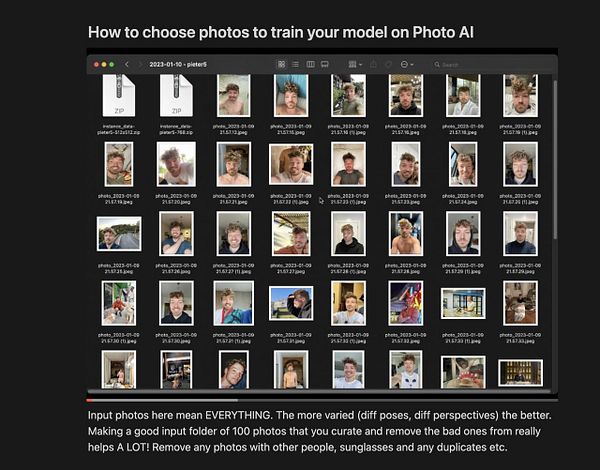
Updating Automatic 11, Installing a new video gpu, today its a day to learn how to train local models :B  #dailywork
#dailywork

📝 prototyped an llm-ollama plugin tonight. models list and it talks to the right places. prompts need more work.
Run openllm dollyv2 on local linux server
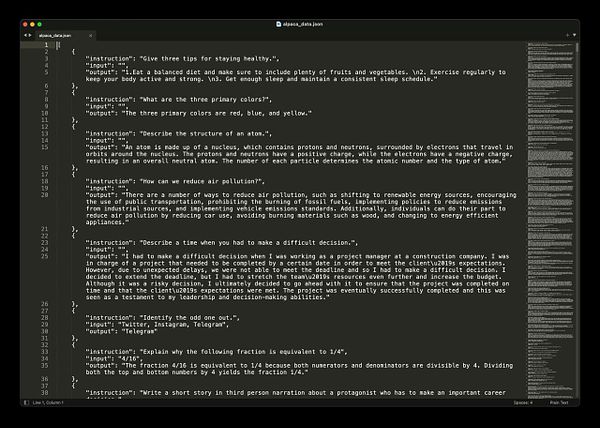
Generate images from trained LoRA  #melies
#melies
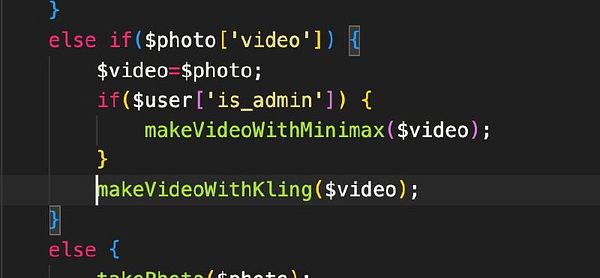
Upgrade to Kamal 2 #vision