Back
Similar todos
test Vision model coop with Llama3  #therapistai
#therapistai
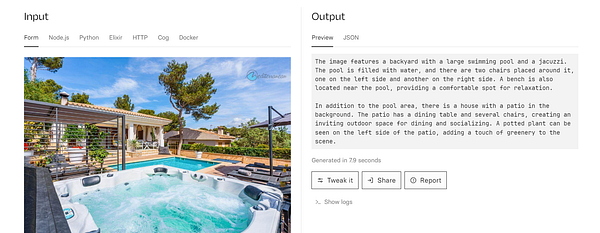
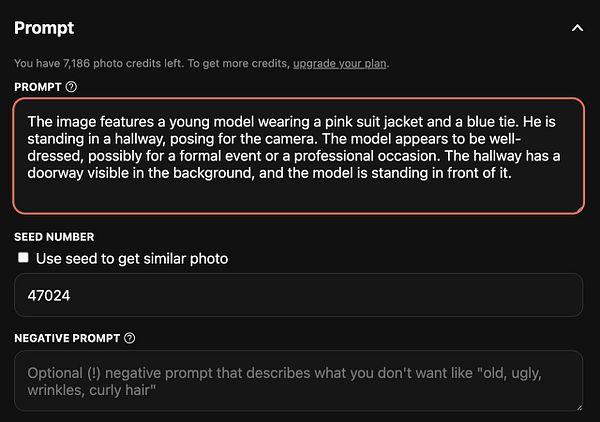
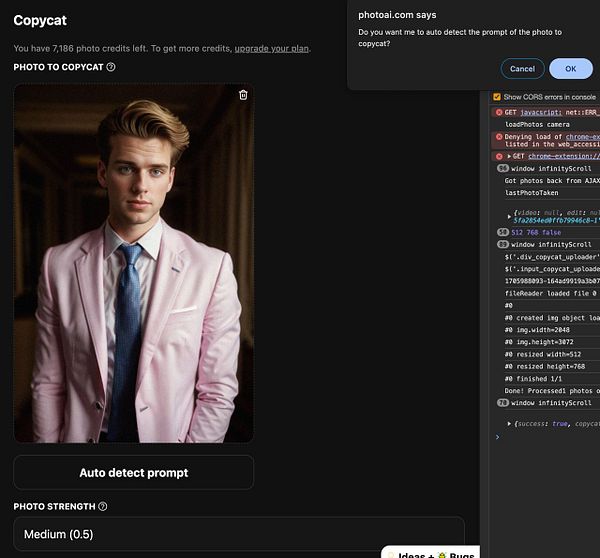
Add support for lensing  #figurine
#figurine
installing relalistic vision model on a1111
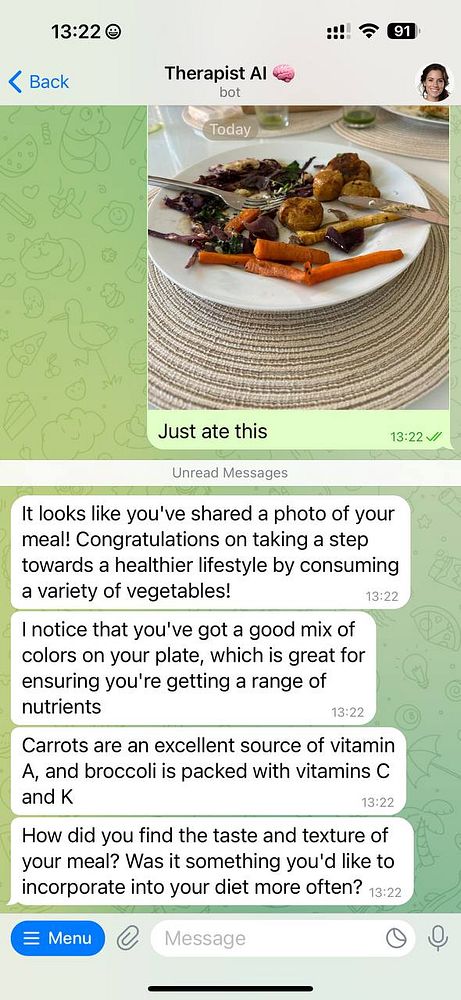
add open source vision model to #therapistai so it can read screenshots and see images/photos
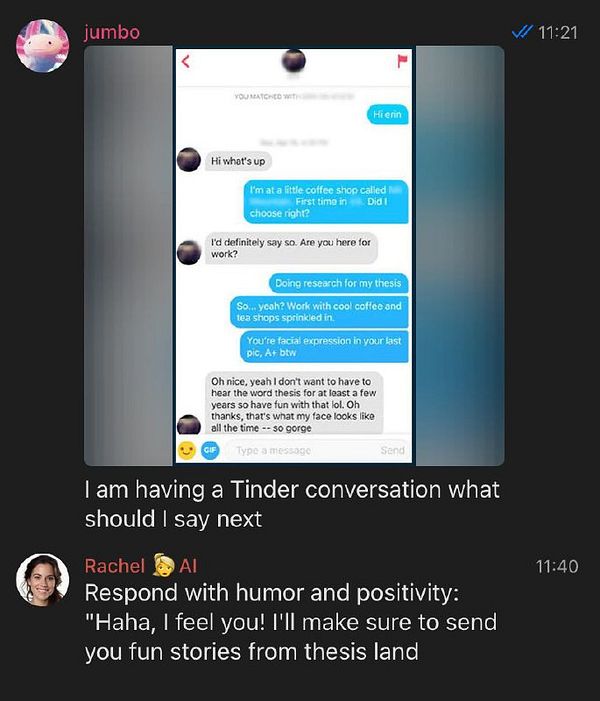
if message sent with image, save the image as prompt_image, then describe it with Llava vision model and send to Groq API #therapistai
try new AI model we made with 3d vision + 3d room segmentation for  #interiorai
#interiorai





Added support for GPT-4 Vision  #pdfpals
#pdfpals
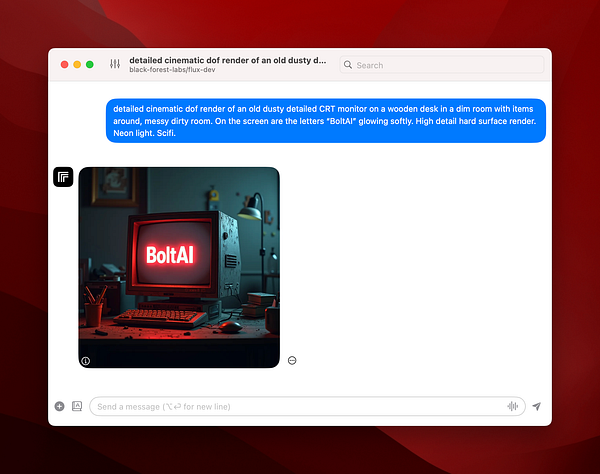
Adding support for the new FLUX text-to-image model  #boltai
#boltai
investigate depthmaps and vision api
prototype a simple autocomplete using local llama2 via Ollama  #aiplay
#aiplay
LoRA training for models  #melies
#melies
Play around with OpenAI Vision API  #jomresplugins
#jomresplugins









Use Android vision library for OCR
Improve LoRA training #melies
Added new pinch based on vision pro documentation  #handkit
#handkit
