Back
Similar todos
Load previous page…
improve crawler logic to better navigate websites #joopie
fixed and ran reddit crawer #dvlpht
fixed crawler bug  #sportstechjobs
#sportstechjobs
fixed crawler bug #sportstechjobs
fixed crawler bug #sportstechjobs
fixed crawler bug #sportstechjobs
fixed crawler bug #sportstechjobs
fixed crawler bug #sportstechjobs
Rewrote scraper. Second attempt is always significantly better than the first one.
watched web scraping node js tuts to improve my crawlers
worked on how to test/keep a scraping project updated more easily
worked up a slightly different engine for my files-to-claud-xml project to make the internal data structure easier to build other tools with.  #research
#research
🤖 Took a stab at rewriting parts of Claude Engineer to make file and project storage better. #research
wrote reddit crawler #dvlpht
finished my first AI-only mini project using Cursor and Claude (download youtube video, transcribe and let user see where in the video the word was mentioned)

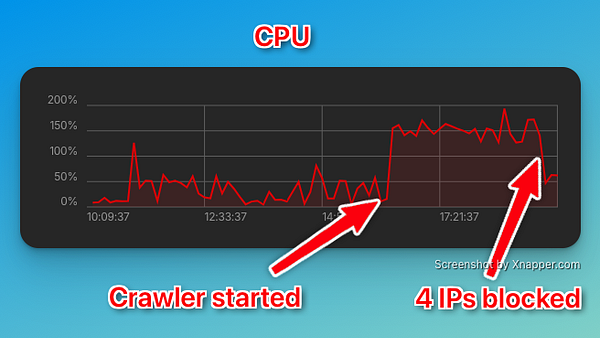
getting crawled at weegee.ch - by aggressive crawlers which brought the site down. Gonna do the simplest thing by blocking the IPs. As a crawler myself I know that this usually causes enough troubles to stop a crawler.
my brother asks me if I know a way to crawl competitor data - with cursorAI it was done in 20m
rewrote one of the running website scrapers to use playwright so that the JS bits get rendered
changed crawler so i can keep css from workdays #sportstechjobs
Spent this morning re-doing my front end with the help of Cursor.