Back
Similar todos
built two more article scrapers using spatula. It's really nice.
more scraper work and I finally figured out how to work around a few issues I couldn't quite wrap my brain around.
worked on another data importer using the new python spatula library. It's not bad, but proving to be a bit more difficult to get my 10+ year old project synced than I'd like
finished job scraper
finished out my day updating scraper-proxy to support css and xpath selectors along with a few features I haven't seen anyone do yet.
finish scraper  #remotejuniorclub
#remotejuniorclub
overhauled another scraper/processor with much better tests and fixed several non-obvious bugs. I should have written tested upfront.
adds a few category pages scrapers using spatula
make new scraper and test it  #plumberjobs
#plumberjobs
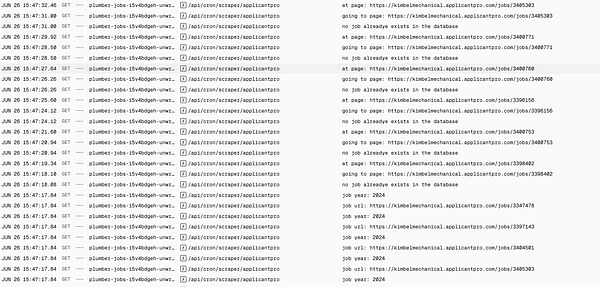
working on some scraping for data analysis  #linkhandy
#linkhandy
continued automating parts of the scraper. I'm now very close to almost 100% hands off.
continue work on scrapers  #pagesonpages
#pagesonpages
🔨 Updates scraper-proxy tool and rewriting/refactoring from the ground up to handle structured data
worked on a scraper service tonight to update it for a few common area layouts and the general collection system
Rewrote scraper. Second attempt is always significantly better than the first one.
working on some a few scrapers for pulling in data vs. just using sheets  #daysuntillatenight
#daysuntillatenight
Updated the way I process the scraping data to minimize errors  #bagsoup
#bagsoup
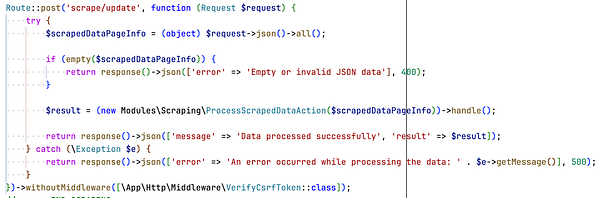
worked on how to test/keep a scraping project updated more easily