Back
Similar todos
Load previous page…
build more scrapers  #pagesonpages
#pagesonpages
worked on how to test/keep a scraping project updated more easily
discuss with friend on how to save space for scraping  #url2format
#url2format
More building a scraping leads csv files
Start work on first scraper  #plumberjobs
#plumberjobs
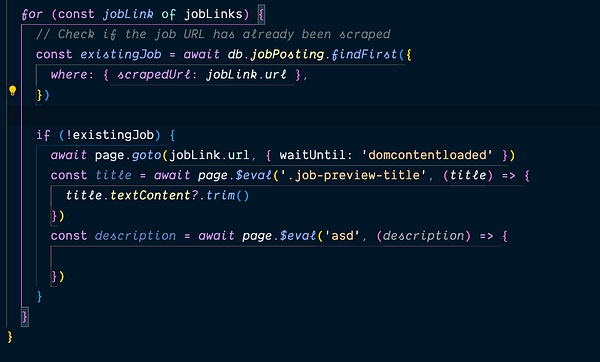
built two more article scrapers using spatula. It's really nice.
make new scraper and test it #plumberjobs
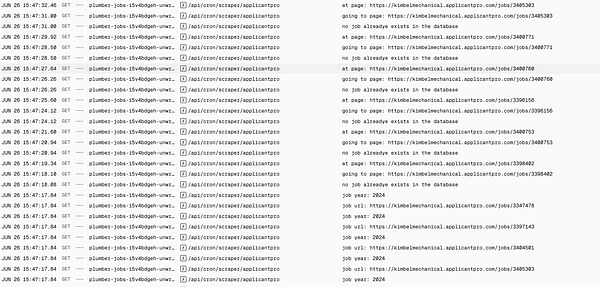
Finally added a log of failing scrapings so I can take action and solve recurring problems  #bagsoup
#bagsoup
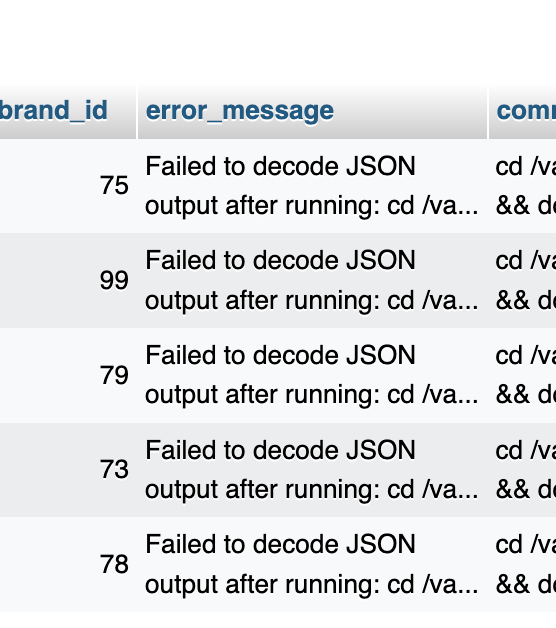
fix scraping script for  #devopsprojectshq it was giving out some nonsense data
#devopsprojectshq it was giving out some nonsense data
added scraping from pages  #scrapebook
#scrapebook
hopped on an audio chat with a friend while we worked through different code problems. I finished three more data scrapers
🔨 Updates scraper-proxy tool and rewriting/refactoring from the ground up to handle structured data
update rake task for loading mods from crawler json data #smuggersclub
See first successful scraping  #life
#life

refactored a scraping library to clean the bulk arguments that are passed to it
finished out my day updating scraper-proxy to support css and xpath selectors along with a few features I haven't seen anyone do yet.
worked on two new  #jobs scrapers using RSS
#jobs scrapers using RSS